МногоМашинное Параллельное Процессирование
MultiMachines Parallel Processing
Архитектурное построение
Многомашинная Параллельная Обработка данных основана на архитектуре распределенных слабосвязанных параллельных машин/модулей с массовой аппаратно-программной масштабируемостью :
- " Систолической Матрице Многомашинных Модулей " -
- " Systolic Multimachines Moduls Array " - S M M A -
реализующей технологию распределенных равноправных клиентов с использованием свободных коллективных вычислительных ресурсов всей системы (или ее части), где процессоры машин модулей относительно независимы друг от друга, имеют собственную оперативную и массовую память и управляют в первую очередь своими собственными данными.
Основное программное обеспечение работает на каждой машине изолировано, параллельные вычисления обеспечиваются специализированным программным обеспечением на нескольких машинах, модулях. Работа распределяется по машинам/модулям в соответствии с распределением данных.
Массовая память разных машин делается совместно доступной для всех пользователей через специализированное программное обеспечение, синхронизирующее доступ к массовой памяти. Оно обеспечивает загрузку на связанные клиентские машины задания/данных для параллельных вычислений в распределенной среде и получение результатов обработки на машину клиента - инициатора параллельных вычислений.
Части логической базы данных реально распределяются и хранятся на разных многомашинных модулях, на разных машинах внутри модулей, при этом индивидуальные узлы не имеют прямого доступа к массовой памяти друг друга.
База данных устанавливаются на распределенной основе в системе с планированием разделения данных по машинам/модулям:
- " Каждому пользователю - свой тип организации данных,
свой тип организации массовой дисковой памяти " -
Старт системы, начальная загрузка и конфигурирование системы выполняется на каждом узле автономно.
Система ввода/вывода электронно связаны через SCSI-3/FC-AL шины, протокол с подтверждением передачи.
Система дистанционной инсталляции, конфигурирования и реконфигурирования программ - стандартные быстрые сетевые коммутируемые сети.
Ввод в работу или вывод из работы отдельных машин/модулей, производится безболезненно для других машин/ модулей, каждому модулю, и машинам в нем, присваиваются индивидуальные виртуальные идентификационные номера, фиксируемые в конфигурационных файлах системы.
Работа с массовой памятью может быть дополнена возможностью автоматического динамического конфигурирования периферии с Монитором Отображения Состояния Системы при изменениях ее конфигурации.
Обеспечение каждой машины системой контроля и мониторинга и протоколирования состояния системы, среды, питания, сбоев и работоспособности электронно-програмных средств.
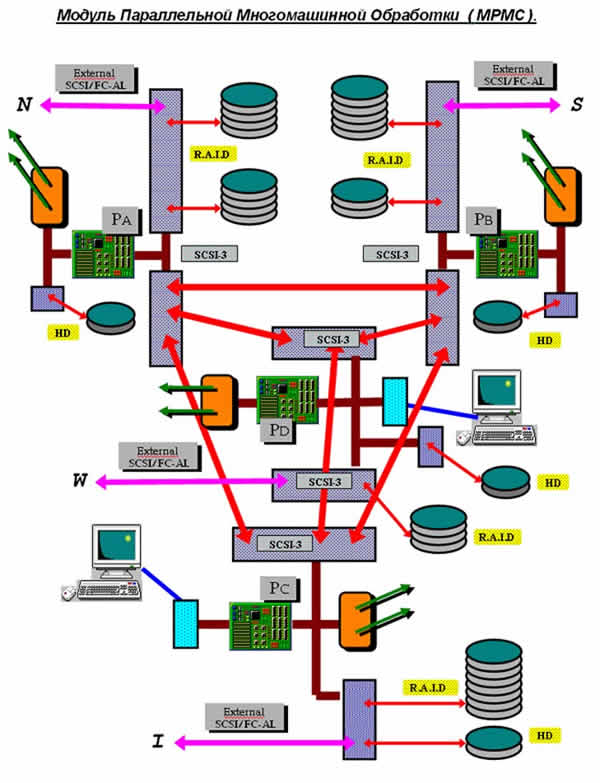
Элементарной функциональной единицей многомашинной системы параллельной обработки является полнофункциональная вычислительная машина оптимально сконфигурированная для выполнения задач параллельных вычислений над распределенными базами данных.
Каждая машина включает процессорный блок с оперативной памятью, многоканальные контроллеры SCSI, стартовый программный HD, RAID - массивы для хранения данных , сетевые контроллеры инициализации и загрузки программного обеспечения.
К машине может быть подключен видео терминальный комплекс, включающим контроллер дисплея, RGB-монитор и клавиатуру, дистанционно разнесенных в помещении от многомашинного модуля.
Модуль представляет собой тетрагональную архитектуру сильно связанных машин, по типу “каждый с каждым”, осуществляемых быстрыми межмашинными SCSI-каналами. Тетрагональная конфигурация является наиболее оптимальной с точки зрения минимального количества связей при максимально параллельном межмашинном доступе к ресурсам, соединенных в модуле, машин.
Систолическая матрица получается прямым соединением соседних модулей противолежащими каналами, узлы которой свободно дополняются в систему по мере необходимости, начиная с одной машины до полноценного модуля.
Взаимодействие с внешними модулями производится через SCSI-каналы, аналогичные межмашинным, по одному на каждое направление (машину соседнего модуля), образуя транспортные каналы систолической матрицы модулей.
Дальнейшее развитие системы видится в развязке RAID-массивов от конкретных процессорных блоков при помощи аппаратных SCSI-коммутаторов, дающих возможность динамично изменять конфигурацию модуля, для максимально быстрого доступа к коллективным ресурсам хранимых и обрабатываемых данных.
При этом достигается максимальная производительность многомашинной обработки с максимальной надежностью, взаимозаменяемостью и работоспособностью системы в целом.
Минимальная конфигурация системы представляет собой простую стандартную сеть вычислительных машин, на которой запущена настоящая математика параллельных вычислений.
Принципиально!
Для параллельной многомашинной обработки не играет роли какая операционная система установлена на отдельных машинах и даже какие процессоры работают в системе, при наличии скомпилированых програмных модулей под эти процессоры.
P.S. Многомашинная Параллельная Обработка данных относится к области технологий двойного применения.
Распределенная обработка
Рассматриваются принципы и конкретная система распределенного решения задач в среде множества персональных компьютеров, объединенных средствами коммуникации, актуальность решения которой следует из того, что:
- Решения такой задачи имеет давнюю предысторию и породила отдельное проблемное направление, связанное с организацией параллельных вычислений, распределением информационной среды, передачей информации, управлением многомашинным комплексом.
- Современные тенденции по использованию локальных вычислительных сетей на базе персональных компьютеров и серверов в качестве систем коллективного пользования не являются приемлемыми - требования к машине коллективного пользования рассматриваются с точки зрения ее архитектурных и операционных возможностей по реализации мультизадачного режима функционирования.
- Архитектура т.н. IBM-совместимых персональных компьютеров, и в первую очередь - серверов, неадекватна проблеме мультизадачности.
- Существует определенный тупик с "большими" информационно-поисковыми и аналитическими программами:
- существующая техника не справляется, а покупать машины среднего и старшего классов в основном экономически не целесообразно, т.к. цены "кусаются" как на "железо", так и на программную оболочку.
Для решения больших задач предлагается фрагментировать их на подзадачи и размещать подзадачи на комплексе взаимосвязанных компьютеров, при осуществлении взаимодействия подзадач по предложенному протоколу.
Рост объемов программ не приводит к конфликту с количественными показателями PC, достаточно фрагментировать и распределять новые фрагменты по множеству компьютеров.
Предлагаемая технология способна дать решение, по эффективности не уступающем решениям на крупных ЭВМ, а по ценам - качественную разницу (сравните цену нескольких персональных компьютеров и цену одной "приличной" Машины - как минимум класса AC-400 и выше - вместе с математикой для нее - UNIX с ORACLE или INFORMIX).
Поддержка языка программирования
Принципы параллельного исполнения программ реализованы в среде языка программирования CAPER ( КАПЕР) где реализована возможность фрагментирования программ, исполнения фрагментов программ на многомашинной основе.
Рассмотрим чисто прикладные решения проблемы обеспечения реального параллелизма языка программирования КАПЕР, создания самостоятельной управляющей среды для запуска и исполнения заданий в комплексе связанных персональных компьютеров.
Наличие в языке КАПЕР конструкций типа:
DO SYNCH/ASYNCH bl1,bl2,...,blK [WITH quant1,quant2,...,quantK] =>
[WITHIN med1,med2,...,medK]
EXECUTE SEQ/SYNCH/ASYNCH bl1,bl2,...,blK [WITH quant1,quant2,...,quantK] =>
WITHIN comp
предписывающей запуск фрагментов программы bl1, bl2, ... , blK на машинах med1, med2, ... , medK с возможным квантованием времени quant1, quant2, ..., quantK порождает ряд процедур по:
- определению текущих состояний всех компьютеров;
- размещению запросов на выполнение;
- определению необходимости транспортировки запускаемых модулей программы;
- транспортировки модулей на вычислительные установки;
- транспортировке параметров для вычислений;
- отслеживанию состояний выполнения всех запущенных модулей;
- принятию решений при возникновении критических ситуаций;
- доставке и получению результатов вычислений.
Рис 1. Структурная схема организации компьютеров для параллельной обработки.
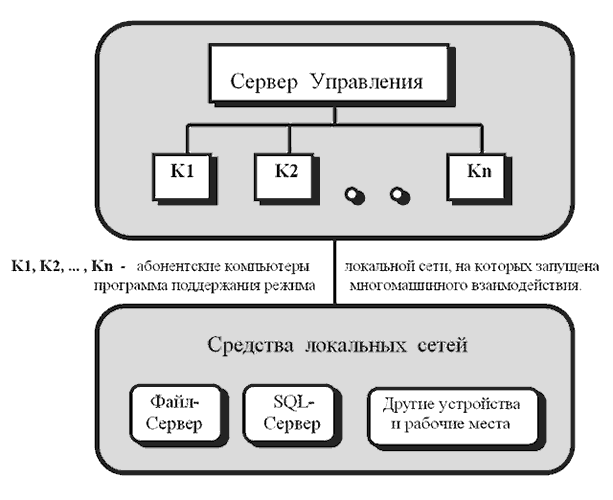
Все управляющие действия осуществляются через общее информационное поле Сервера Управления (СУ).
В качестве последнего в силу последующих определений может выступать простой персональный компьютер.
На СУ заданы:
- Раздел Управления с Файлами Управления,
- Раздел Приема/Передачи фактических Параметров для выполняемых модулей программ (в языке КАПЕР - блоки команд),
- Раздел Транспортируемых Файлов,
- Раздел Размещения Результатов Вычислений.
Все запущенные программы регистрируют готовность (собственную и компьютера) в первом Управляющем Файле:
- указывается логическое имя машины,
- отметка о готовности,
- дата и время регистрации.
Второй Управляющий Файл используется для регистрации заданий. Задание осуществляется записью следующих компонент:
<исполнитель>, <запрашивающий>, <идентификатор задания>, <статус задания>,
<приоритет компьютера>, <приоритет задания>, <текст задания>, <стиль задания>,
<транспортирование>, <результат>, <время выставления задания>, <дата>,
а также несколько других служебных, где:
<исполнитель> - логическое имя компьютера, которому обращено данное задание, или указание на то, что данное задание может быть выполнено любым из свободных компьютеров, либо указания на то, что данное задание должно быть выполнено всеми компьютерами или группами компьютеров.
<запрашивающий> - логическое имя компьютера, выставившего данное задание.
<идентификатор задания> - уникальное имя задания, формируемое программой управления при размещении задания к выполнению.
<статус задания> - состояние задания, которое имеет следующие значения:
" активизация задания "
" задание выбрано к исполнению "
" нормальное завершение задания "
" аварийное завершение задания "
" задание приостановлено "
" задание прервано по требованию "
<приоритет компьютера> - собственный приоритет компьютера.
<приоритет задания> - планируемое значение приоритетности задания.
Все задания в очереди размещаются исходя из диспетчерского приоритета, определяемого суммой:
<приоритет компьютера> + <приоритет задания>.
В реализованном варианте системы MULTICOM приоритет задания устанавливается только подсистемой запуска задач, в то время как для многомашинного режима программ КАПЕРа используются приоритеты компьютеров.
<текст задания> - либо командная строка ОС (DOS, Windows, OS/2, UNIX), либо bli(ai1,ai2,...,aik) - задание стартовать блок с параметрами по
DO SYNCH/ASYNCH bl1,bl2,...,blK [WITH quant1,quant2,...,quantK] =>
WITHIN med1,med2,...,medK
либо запись bl1(a11,a12,...,a1k), bl2(a21,a22,...,a2l), ... , blK(ai1,ai2,...,aim)
списка блоков с параметрами и, возможно, квантами времени, и которые должны быть выполнены на указываемом компьютере по команде:
EXECUTE SEQ/SYNCH/ASYNCH bl1,bl2,...,blK [WITH quant1,quant2,...,quantK] =>
WITHIN comp
<стиль задания> верен только для программ языка КАПЕР и определяет режим запуска задания - списком, синхронный или асинхронный по команде EXECUTE, или отдельным блоком по команде DO.
<транспортирование> - имеет значение тогда, когда фрагменты программы транспортируются с компьютера-заказчика на компьютер-исполнитель.
<результат> - указание на файл результатов вычислений, возвращаемых запрашивающему компьютеру.
<время выставления задания> - время, когда выставлено задание.
<дата> - дата задания.
<время выбора задания к исполнению> - время, когда задание принято к обработке.
<время завершения задания> - время, когда задание завершено независимо от результатов.
<дата выбора> - дата приема задания.
<дата завершения> - дата завершения задания.
Принципы реализации заданий
Программой управления просматривается список заданий каждого компьютера , позиция <исполнитель> которых совпадает с собственным логическим именем компьютера или группы компьютеров, и <статус задания> которого в состоянии "активизация задания".
Будет выбрано задание с наибольшим диспетчерским приоритетом и выставлены признак "задание выбрано к исполнению", время и дата приема задания к выполнению, имя компьютера-исполнителя.
Далее, если позиция транспортирования не пуста, загружаются фрагменты / объектные или исходные модули программы / и выполняются адекватными командами DO или ATTACH.
После завершения запущенных задач результаты их выполнения компонуются в файлах; в поле <результат> устанавливаются имена данных файлов. Если задание завершается аварийно, то возвращается исчерпывающая информация.
В тех случаях, когда на тот или иной компьютер необходимо транспортировать файл, в том числе - и программу, используется команда CAPER (или ее аналог в MULTICOM) :
TRANSPORT <список имен файлов> TO <список имен компьютеров>
Ожидание результатов по конкретному асинхронному запуску в программе-инициаторе осуществляется с помощью команд КАПЕРа:
WAIT MULTICOM [<идентификатор>] [BY <имя блока>]
WHEN <событие> DO <имя блока>
В первом случае ожидается установка завершения задания. Процесс ожидания проистекает с выполнением процедуры - блока команд. Возможны вариации ожидания (ждать определенного состояния задания или компьютера, группы компьютеров или группы заданий).
Во втором случае необходимое состояние определяется в качестве события, возникновении которого будет обработано блоком - процедурой.
Ниже приводится неполный набор управляющих команд системы MULTICOM:
Загрузить объектный модуль КАПЕРа
Исполнить блок КАПЕРа
Исполнить задачу КАПЕРа
Исполнить список КАПЕРа
Исполнить задачу DOS
Создать объектный модуль КАПЕРа
Копировать файл
Транспортировать файл
Транспортировать список файлов
Показать диски
Показать директории
Установить активную директорию
Асинхронный модуль КАПЕРа
Загрузить и исполнить асинхронные блоки КАПЕРа
Исполнить асинхронный блок КАПЕРа
Исполнить асинхронный список КАПЕРа
Передать значение.
В предлагаемом подходе возможно:
- Распределять файлы помимо серверов на собственных носителях компьютеров многомашинной системы.
- Вести распределенную обработку информации, не загружая сеть - в нашем случае информационно-поисковые задачи могут решаться на компьютере в поле данных, размещенных на собственном винчестере, в режиме: короткий запрос - Описание Задачи и короткий ответ - Файл Результата (в системах, написанных на основе DBASE-технологии и некоторых других, происходят постоянные копирования баз данных и файлов на рабочие места, что и приводит к перегрузкам коммуникационных средств).
- Надежное функционирование систем - в комплексе машин могут быть установлены компьютеры:
a) с одинаковыми логическими именами - несколько таких машин должны решать одну и ту же задачу; в служебных полях Файла Регистрации и Запросов устанавливается количество таких компьютеров и, в случае выхода из строя одной из машин, задача будет решена дублирующими (их количество определяется на основе статистики отказов);
b) с разными логическими именами запросы на решение одной и той же задачи могут адресоваться к группе компьютеров с разными логическими именами. Обеспечивается надежность в регламентации доступа к информации, т.к. информация может располагаться не на сервере, а на собственном винчестере компьютера - абонентской машине сети, доступ к которой может регламентироваться комплексом паролей. Исходная информация не циркулирует в сети - по ней транспортируются только запросы/ответы, упрощается проблема защиты от электронных систем съема информации со средств коммуникации (в случаях серверного хранения необходимы регламентации сетевыми средствами и пр.)
Задачи, для которых актуально предлагаемое решение
Многомашинное и многопроцессорное решение задач ценно само по себе и не требует особой мотивации. То, что касается конкретных решений в языке КАПЕР никак не относится к его идеологической подоплеке, т.е. возможны иные решения по параллелизму, зависящие от той вычислительной среды, в которую внедряется КАПЕР.
Предлагаемые решения важны с точки зрения сегодняшнего состояния в области компьютерной техники и вычислительных сред в целом.
Современные тенденции по использованию локальных вычислительных сетей на базе персональных компьютеров и серверов в качестве систем коллективного пользования не являются приемлемыми - требования к машине коллективного пользования рассматриваются с точки зрения ее архитектурных и операционных возможностей по реализации мультизадачного режима функционирования. Очевидно, что архитектура т.н. IBM-совместимых персональных компьютеров, и в первую очередь - серверов, неадекватна проблеме мультизадачности.
Напомним, что возможность эффективной мультизадачности вычислительной установки возникает тогда, когда:
- Процесс ввода-вывода управляется не центральным, а специализированным процессором.
- Ввод-вывод допускается непосредственно в оперативную память компьютера.
- Существует эффективная электронная система разделения оперативной памяти как ресурса между одновременно выполняемыми процессами.
- Вычислительная установка обеспечена системой электронных прерываний, обеспечивающих реакцию программ на асинхронные события без использования ресурсов процессоров.
Именно по этим причинам качественный рост сложностей задач приводит к периодическому обновлению парка компьютеров (за последние 8 лет произошло четыре смены поколений), в то время как концептуальный тупик архитектуры сохраняется.
Внедрение технологии приведет к определенной независимости от архитектурных тупиков. Существенной проблемой является разрешение вопроса переделок существующих систем в концепции многомашинности.
Так как опыт таких переделок имеется (операционный день банка и банковская аналитическая система), то правила таковы:
- разделение интерфейсной пользовательской части большой программы и функциональной ее части;
- в пользовательскую часть вставляются фрагменты формирования запросов и получения-разборки ответов; в функциональную часть - средства разборки запросов и формирования ответов;
- функциональная часть в случае необходимости "разрезается" на несколько логически и информационно независимых модулей, которые размещаются на отдельных компьютерах;
- в случаях особых нагрузок на те или иные модули (и следовательно - компьютеры), можно установить дополнительный компьютер с идентичным модулем и тем же логическим именем; режимы их функционирования можно регулировать, если очевидный - кто первый увидел задание для себя, тот его и обработал, - не является удовлетворительным (такие случаи могут быть; существует несколько вариантов решений).
|